
In case you have not noticed from the multiple TV ads, for a few years now IBM has been positioning itself as a Big Data company, with its Watson platform and cloud-based services. One of them is the Alchemy Language API, which packs together functions for text analysis and information retrieval. As part of learning how to handle this API from R, I tried it on a news story about a sci-fi book publishing business. Overall, the results were strong, although not without some amusing quirks…
Reading comprehension courses instruct their students to focus on five questions: who, what, when, where, and why. In the realm of natural language processing, the answer to the first one – who? – is provided by the tools collectively known as Information Retrieval (IR). A big part of IR is entity detection – telling a user whether there are references to persons, places, companies, dates, etc. – in the text. A recent graduate of QAC, Mansoor Alam ’15, pointed me towards IBM BlueMix – a collection of cloud-based services. Alchemy Language API is one of them and it is notable for having entity detection function, in addition to sentiment and emotion classification.
IBM BlueMix provides SDK (software development kit) libraries for several languages: Java, Python, Javascript (Node.js), but not R. Fortunately, the protocol for submitting HTTP requests to the API is pretty straightforward and can be easily implemented in R. All it takes is to specify a body of the request, and submit it using POST method. The code snippet at the bottom of this page implements a request to the entity detection endpoint, for the case where the source text resides on the web and is identified by its URL. For my example, I semi-randomly chose a news report from the front page of Publishers Weekly. The premise of the story, briefly, is that Kensington Publishing (a company) is launching a new imprint (a subsidiary company operating under its own name) – Rebel Base Books, – which will publish science fiction as e-books. The story contained a sentence quoting Martin Biro – an editor at Kensington who will be overseeing the new imprint:
“As a lifelong fanboy raised on a steady diet of Star Trek and Lord of the Rings, I couldn’t be more excited to boldly go where Kensington has never gone before,” Biro said in a statement.
You will soon see why this sentence is important for the story.
The API can return several kinds of information about an entity. The most basic is the type of entity: is it a place, a person, a company? In addition, the API can also provide the knowledge graph for the entity. A knowledge graph is a hierarchical tree, tracing the concepts from the most generic to specific. For instance, the knowledge graph for “Speaking” is “/activities/services/resources/skills/speaking”. The knowledge graph for Philip K. Dick (a famous sci-fi author) is “/people/authors/philip k. dick”. Finally, the API can also provide disambiguation information: URLs to entries in knowledge databases covering specific items.
As part of the free plan with Alchemy Language API, a user gets 1,000 transactions per day. Requesting knowledge graph in addition to entity type counts as an extra transaction. Sentiment and emotion detection within the text count as transactions as well. As a result, a single HTTP request may easily consume 3 or 4 transactions out of your daily quota.
Below is the table combining results of entity type and knowledge graph classification for the news article from Publishers Weekly. Putting the results side by side leads to a surprising conclusion: on quite a few occasions the results do not match. For instance, Kensington (line 2) is labeled as Person, but knowledge graph correctly places it with brands. In contrast, Barb Hendee (author of Through a Dark Glass) is placed with “/species/barbs/barb hendee” by the knowledge graph, while its type is Person. Dark Glass is classified as Person (maybe influenced by composer Philip Glass?), while knowledge graph assigned it to “recognizable accessories”.
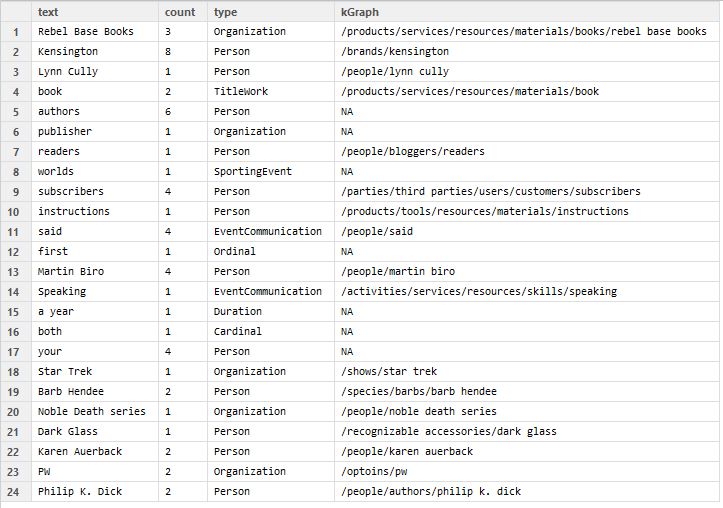
The most striking, and funny, result is in line 18: entity detection algorithm classified Star Trek as Organization … The knowledge graph, however, correctly placed it with TV shows (unless that category somehow also includes Broadway shows). It appears that the two systems operate independently from each other and do not compare their results. The ultimate losers, though, are the fans of Tolkien’s books and Peter Jackson’s movies: Lord of the Rings was not recognized as an entity.
The over-emphasis on organizations may be explained by the fact that Alchemy Language API positions itself as a tool for working with corporate news data: its demo pages for the Language API and News Data API highlight these applications. In the realm of stories about companies being sold or bought, of CEOs moving to new positions, of quarterly reports and PR communication, the typology of entity detection algorithm does not seem that strange. However, this limits the applicability of the API for those of us who would like to use it in language domains other than corporate data.
The code below illustrates how to submit an HTTP POST request to the AlchemyLanguage API, requesting entity detection of a page that is located online and is specified with data_url argument. For a full example, along with more commentary, please visit QAC’s dokuwiki post on the same topic.
library(httr) library(jsonlite) ## end point for the API api_url = "https://gateway-a.watsonplatform.net/calls/url/URLGetRankedNamedEntities" ## location of data data_url = "http://www.publishersweekly.com/pw/by-topic/industry-news/publisher-news/article/71524-kensington-launches-digital-speculative-fiction-imprint.html" ## construct the body of the request body = list( ## you will get API key when you register for BlueMix and activate Alchemy API apikey=api_key, ## URL of the text on the web url=data_url, ## maximum number of entities to retrieve maxRetrieve=50, ## language model to use - English news model="en-news", ## request result in JSON format outputMode = "json", ## count co-references coreference=1, ## include disambiguating information disambiguate=1, quotations=1, ## whether to include knowledge graph - this consumes 1 extra request knowledgeGraph=1, ## whether to include linked data to the back-end knowledge databases Alchemy uses linkedData=1, ## whether to include source text showSourceText = 1, ## how should the source text be processed when it is ingested from an HTML page ## "cleaned" means remove ads and links sourceText = "cleaned", ## this argument tells Watson not to use our request for its own training "X-Watson-Learning-Opt-Out"="true") ## POST() is a function in httr package s = POST(url=api_url , body=body , encode="form" ) w = fromJSON(content(s, as="text", encoding='UTF-8')) kG = w$entities$knowledgeGraph ent = w$entities